


How AI PMs and AI Engineers Collaborate on Evals
A deep dive into the critical collaboration patterns that separate successful AI products from expensive experiments

👋 I’ve been posting less lately as I worked on shaping more of a structured list of topics to cover. I’m covering these topics in more depth during an upcoming cohort - you can learn more about that here!
By now, the secret is out: building great AI products relies on great evals. Writing evals is quickly becoming a core skill for anyone building AI products (which will soon be every PM). Yet while we're getting better at understanding what evals are and why they matter, there's surprisingly little guidance on how Product Managers and AI Engineers should collaborate on them. This collaboration is the difference between evals that look good on paper and evals that actually drive product success.
As someone who's helped build evaluation systems at scale across hundreds of companies I've seen this partnership make or break AI products worth millions. The success of an AI product isn't just about a brilliant idea or a powerful model; it's about how these two roles collaborate to define, measure, and iterate on what "good" truly means. The evaluation framework isn't just code or metrics—it's the shared language between product and engineering that makes great AI products possible.
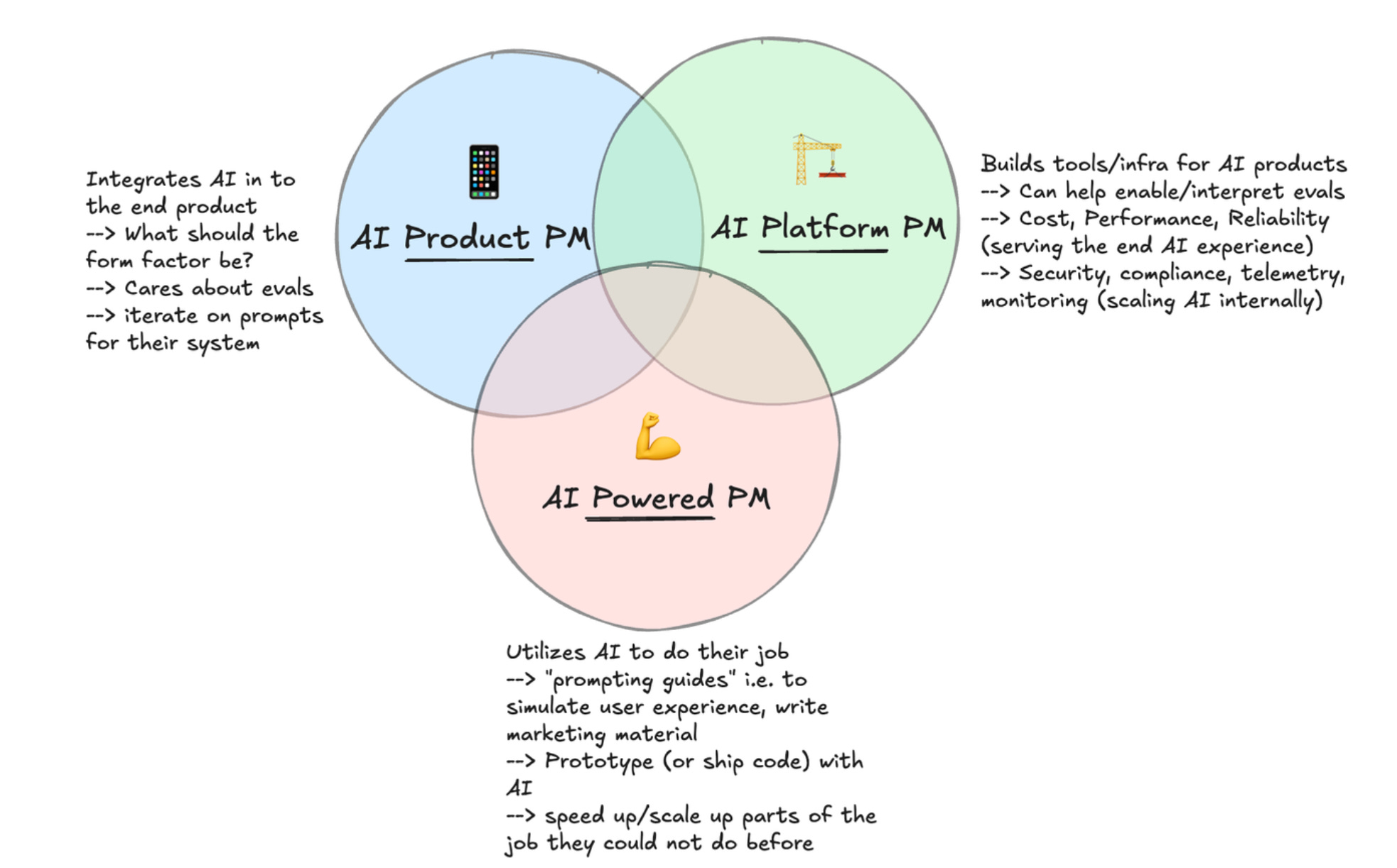
The Three Archetypes of AI Product Manager
Before diving into collaboration patterns, let's address a common question: "Is an AI PM just a PM that uses AI in their day to day?"
Not quite. Today's AI PMs typically fall into three archetypes:
The Core Product PM: Lives and breathes the end-user experience. They obsess over form factor, packaging, and how AI seamlessly integrates to solve real problems. They are the voice of the customer.
The Platform Builder: The architect of AI infrastructure. Their world revolves around managing costs, ensuring reliability, and making critical model selection decisions. They build the scalable foundations.
The AI-Powered PM: A new breed who leverages AI as their core toolkit. They're adept at prompting, rapid prototyping, and even writing code. They blur the lines between product, engineering, and design.
Most PMs wear all three hats at different times. The key is recognizing where your strengths lie and building complementary teams. But regardless of your archetype, collaboration on evals is non-negotiable.
Let’s see how evals actually fit in to an AI Product workflow
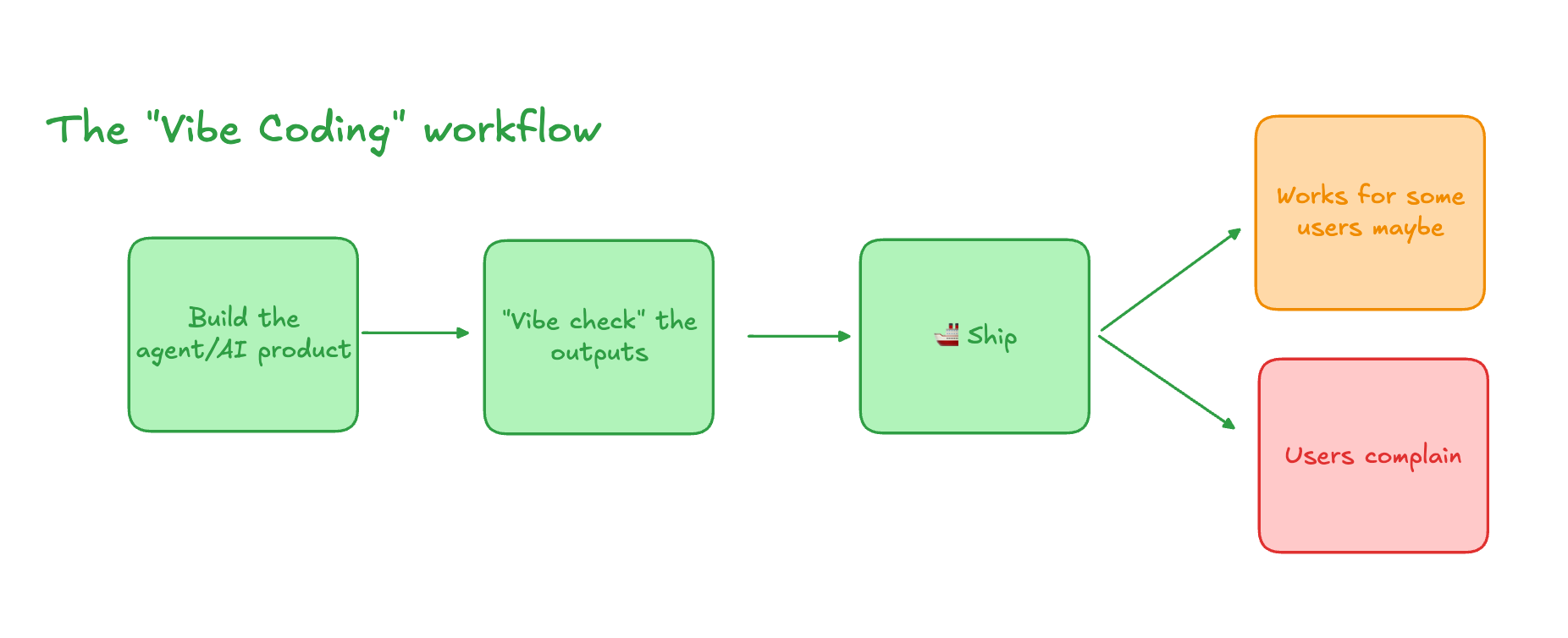
Stage 1: "Vibe Coding" aka AI Prototyping
At the dawn of a new AI product, the energy is all about speed and possibility. But even in this fluid, creative stage, the seeds of a strong evaluation partnership are sown.
The AI PM's Role (The "Why")
The Product Manager champions the user problem and the core hypothesis. They bring the "vibe"- a clear vision of the desired user experience. Their question is, "If this works, will it solve a real problem and delight our users?"
Real example from my Spotify days: When building playlist generation features, PMs would often sit with engineers during initial prototyping sessions, providing immediate feedback like "That transition feels jarring" or "This captures the morning commute vibe perfectly."
The AI Engineer's Role (The "How")
The AI Engineer rapidly translates this vision into a working prototype. They are the masters of the possible, grabbing the best models and tools to see if the "vibe" can be made tangible.
Collaboration on Evals
Formal evals don't exist here, but the collaborative evaluation has already begun. It's a rapid, conversational loop:
Shared Language Development: PM provides qualitative feedback ("That response feels too robotic"), engineer tweaks prompts in real-time
Edge Case Discovery: Together, they throw curveballs at the prototype to understand its boundaries
Success Criteria Sketching: Even informally, they're building consensus on what "working well" looks like
Pro tip: Document these early conversations. They become the foundation for your formal evaluation criteria later.
Stage 2: "Write the Eval" - The Crucible of Collaboration
This is where the partnership is truly tested and forged. Moving past the "vibe" requires making abstract goals concrete, and this is impossible to do in a silo.
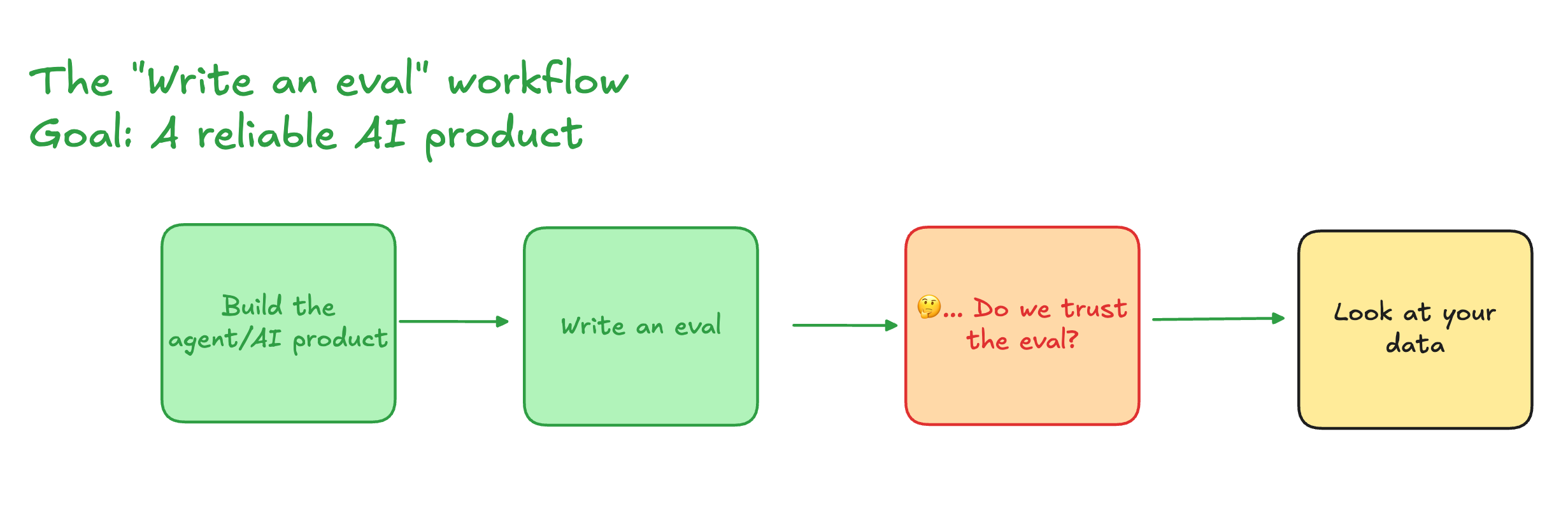
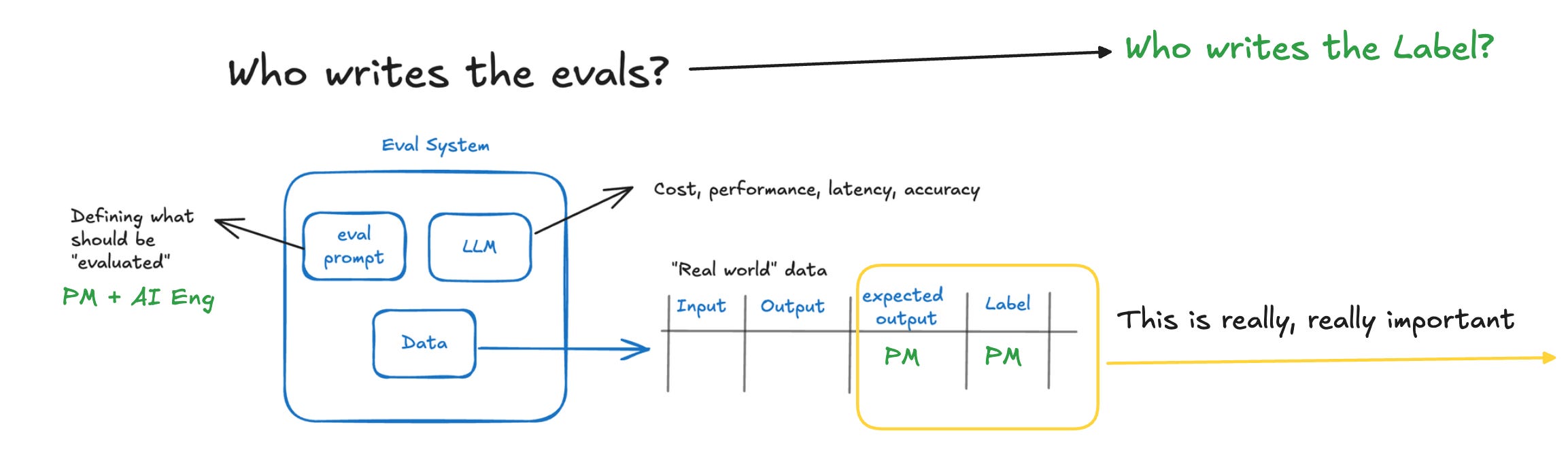
But here's where teams often get stuck: Do we trust this initial Eval? And who is ultimately responsible for evals—the AI PM or AI Engineer?
The answer isn't what you'd expect. It's both, but in different ways:
The PM owns the "what": What constitutes success from the user's perspective
The Engineer owns the "how": How to reliably and efficiently measure that success
Together, they own the "why": Why these specific metrics matter for the business
This shared ownership is uncomfortable for teams used to clear swim lanes, but it's essential for AI products.
This is where the partnership is truly tested and forged. Moving past the "vibe" requires making abstract goals concrete, and this is impossible to do in a silo. Let’s get deeper on this.
The PM's Role (Defining "Good")
The PM takes the lead in defining what to measure, translating the user story into a rubric. They own:
Creating the "Golden Set": Curating examples representing the full spectrum of user interactions
Defining Quality Dimensions: Is it accuracy, tone, safety, helpfulness?
Prioritizing Failure Modes: What are the unacceptable outcomes we must prevent?
The AI Engineer's Role (Measuring "Good")
The AI Engineer architects the evaluation framework:
Technical Implementation: Determining if simple keyword matching suffices or if model-based evaluation is needed
Statistical Rigor: Ensuring evaluations are reliable and significant
Scalability: Building systems that can evaluate up to millions of outputs
The Three Critical Collaboration Points
1. Co-authoring Evaluation Prompts
This isn't a handoff—it's a pair programming session for prompts. Here's a real example from my work:
# PM provides the context and examples
"""
User intent: Asking for a refund
Key considerations:
- User might be frustrated
- Need to maintain brand voice while being helpful
- Must follow policy but show empathy
Good examples:
1. "I understand your frustration. Let me help you with that refund right away..."
2. "I'm sorry to hear about your experience. I'll process your refund immediately..."
Bad examples:
1. "Refunds are against our policy." (too rigid)
2. "Sure thing! Money back!" (too casual, no empathy)
"""
# Engineer structures this into an evaluation prompt
evaluation_prompt = """
You are evaluating customer service responses for refund requests.
Rate the response on:
1. Empathy (0-5): Does it acknowledge user frustration?
2. Helpfulness (0-5): Does it provide clear next steps?
3. Brand voice (0-5): Professional yet warm?
4. Policy adherence (0-5): Follows refund guidelines?
Response to evaluate: {response}
User message: {user_message}
Provide scores and explanation.
"""2. Joint Labeling Sessions
The most underrated activity in AI product development. Schedule regular sessions where PM and engineer label data together:
Surfaces Ambiguities Early: A PM might label a response "unhelpful" for missing emotional cues, while an engineer sees it as "factually correct"
Builds Shared Mental Models: These discussions refine evaluation criteria until they capture both technical correctness and user experience
Creates Alignment: When disagreements arise in production, you have precedent for resolution
From experience: At Cruise, we'd have weekly "edge case parties" where PMs, subject matter experts (QA) and engineers would review the weirdest self-driving scenarios together. These sessions were invaluable for building shared understanding.
3. The Statistical Significance Conversation
One of the three crucial questions every team faces: How many labels are enough?
This isn't just an engineering decision. PMs must understand and co-own this:
For initial eval set: Start with 100-500 examples per key use case
For production validation: Sample size depends on traffic and risk tolerance
For A/B testing models: Need statistical power calculations based on expected improvement
The PM brings business context ("We can't afford false positives in payment flows"), while the engineer brings statistical expertise ("We need N examples for 95% confidence").
Stage 3: "Evals in Development and Production" - The Shared Dashboard
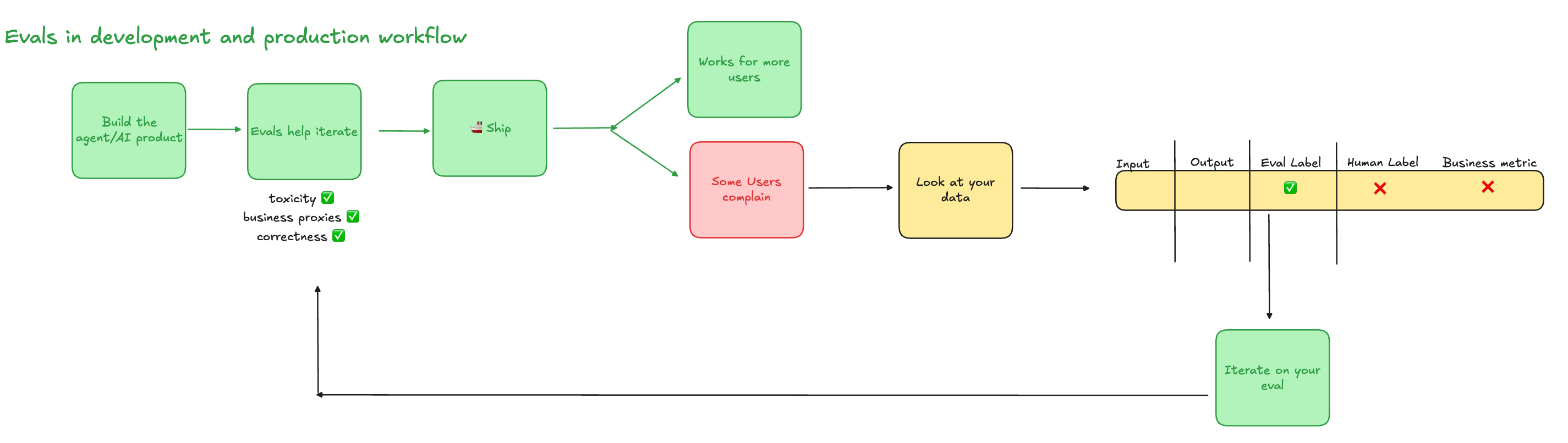
With the product live, the evaluation framework becomes the team's shared operating system.
When Things Go Wrong: The Launch That Sucks
Here's a scenario every AI team faces: What happens when you launch your AI application—and it sucks?
I've been there. At Cruise, we once deployed a model that scored perfectly on our evals but made passengers carsick with jerky movements. The technical metrics were green, but the human experience was red.
This is where the PM-Engineer partnership is tested most:
Immediate Triage: Engineer checks if it's a technical failure (latency, errors), PM checks if it's an experience failure (user complaints, business metrics)
Root Cause Analysis: Together, trace the gap between what evals measured and what users experienced
Eval Evolution: Add new evaluation criteria that would have caught this issue
Post-Mortem: Document the blind spot for future products
The teams that recover quickly from bad launches are those where PM and Engineer debug together, not point fingers.
The PM's Role (The Business Impact)
The PM owns the "so what?" question:
Correlation Analysis: "Our evals show 5% accuracy improvement, but did user retention move?"
Segment Deep-Dives: "Why are enterprise users complaining when our evals are green?"
Strategic Trade-offs: "Should we optimize for speed or accuracy given our business goals?"
The AI Engineer's Role (The Performance Engine)
The engineer maintains the technical excellence:
CI/CD Integration: Evals run on every deployment
Drift Detection: Monitoring for model degradation
Performance Optimization: Balancing eval comprehensiveness with latency
How to handle the “hard questions”:
I think about this as 3 important Questions to discuss with your team:

The Disagreement Protocol
What happens when the eval says "good" but humans say "bad"? You need a pre-agreed process:
The Tiebreaker: Designate a domain expert (often the PM or Subject Matter Expert) as the final arbiter
The Investigation: Engineer digs into why the eval missed it
The Evolution: Together, add this case to your eval set
The Business Metrics Integration
This is where many teams fail. You need unified dashboards showing:
Eval Score | Human Feedback | Business Metric | Action
----------|----------------|-----------------|--------
0.95 | 👍 | +5% conversion | Ship it
0.97 | 👎 | -2% retention | Investigate
0.89 | 👍 | +8% revenue | Understand whyThe Continuous Improvement Loop
Successful teams have a weekly ritual, something like:
Monday: Review weekend anomalies together
Wednesday: Label new edge cases discovered
Friday: Plan eval improvements for next sprint
The Patterns of Success
After working with dozens of AI teams, the successful ones share common traits:
1. Technical Product Managers
Let's address the elephant in the room: How technical does an AI PM need to be?
You don't need to implement transformers from scratch, but you do need:
Statistical Literacy: Understanding confidence intervals, sample sizes, and significance. You can learn these on the job and through iteration.
AI Intuition: Knowing why a model or prompt might fail helps you design better evals. I’ll be covering more on AI Intuition in a future post.
Technical Empathy: Understanding engineering constraints leads to better trade-offs
Action item: If you're a PM without technical background, pair with engineers on queries and analyses. Learn by doing. Start with SQL, then basic statistics, then model behavior patterns.
2. Well-Scoped AI Products
The most successful AI products are often the simplest. They:
Solve a specific, well-defined problem
Have clear success metrics
Possess straightforward evaluation criteria
Anti-pattern: The "AI for everything" product that tries to be too smart and becomes impossible to evaluate properly.
3. Shared Ownership Mindset
In traditional software, PMs own "what" and engineers own "how." In AI:
PMs must understand enough of "how" to define meaningful evals
Engineers must understand enough of "what" to build the right measurements
Your Action Plan
Ready to level up your PM-Engineer collaboration on evals? Here's your roadmap for going from prototype to implementation with your AI Engineer:
Week 1: Schedule a "vibe alignment" session. Discuss what success looks like qualitatively before diving into metrics.
Week 2: Run your first joint labeling session. Start with just 50 examples. Focus on finding disagreements—they're gold for refining your evaluation criteria.
Week 3: Co-create your first evaluation prompt. Make it a true collaboration, not a handoff.
Week 4: Build a simple dashboard combining eval scores with one business metric. Keep it simple but make it visible to the entire team.
Week 5: Run your first "eval post-mortem" on a feature that didn't perform as expected. No blame, just learning.
The Path Forward
The age of AI demands a new kind of product development—one where the boundaries between product and engineering blur, where success is defined not by shipping features but by delivering measurable value, and where the evaluation framework is the shared language that makes it all possible.
The teams that master this collaboration won't just build AI products—they'll build AI products that matter. And it all starts with recognizing that evals aren't just an engineering concern or a product requirement—they're the shared responsibility that brings great AI products to life.
Resources:
Lenny x Aman Collaboration piece on evals - if you haven’t read it yet
amank.ai for a bunch of talks I’ve given on evals
https://hamel.dev/ - Hamel has some great eval resources
Want to dive deeper into the practical skills needed for AI product management? Check out my upcoming Maven course: "Prototype to Production: The AI PM Playbook". Use code EVALS for a discount.
Questions about implementing these patterns in your organization? Find me on LinkedIn or email me at amannaipproduct@gmail.com. I love talking shop with teams building in the AI space.