
⚡️Mastering Evals as an AI PM (Session Recap)
Check out this interactive post on writing evals building off my lightning session from last week

Note: If you want to read the post that kicked off this session, definitely check out Beyond vibe checks: A PM’s complete guide to evals that I wrote with
!
How to Measure and Improve Your AI Products with Evals (Step-by-Step)
Last week, I hosted a hands-on lightning session through Maven, breaking down exactly how you can master evals as an AI PM. As a note to set expectations this session is more of a foundation for AI Evals - you’ll walk away knowing the basics and having written your first eval. In the future, I plan to cover implementing evals in your workflow, optimizing on your data evals, and more. If you missed the session (or just want a recap), here's a simple step-by-step guide to what we covered👇🏽
Resources:
Step 1: Start with Realistic AI Data
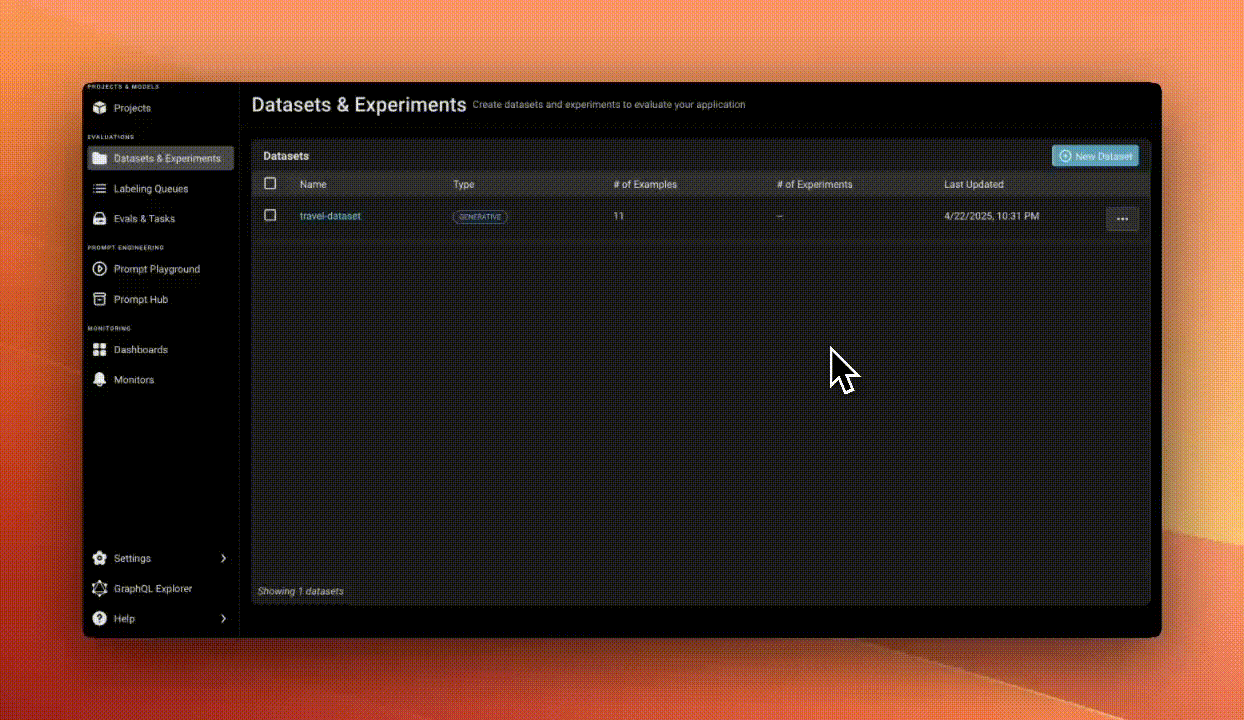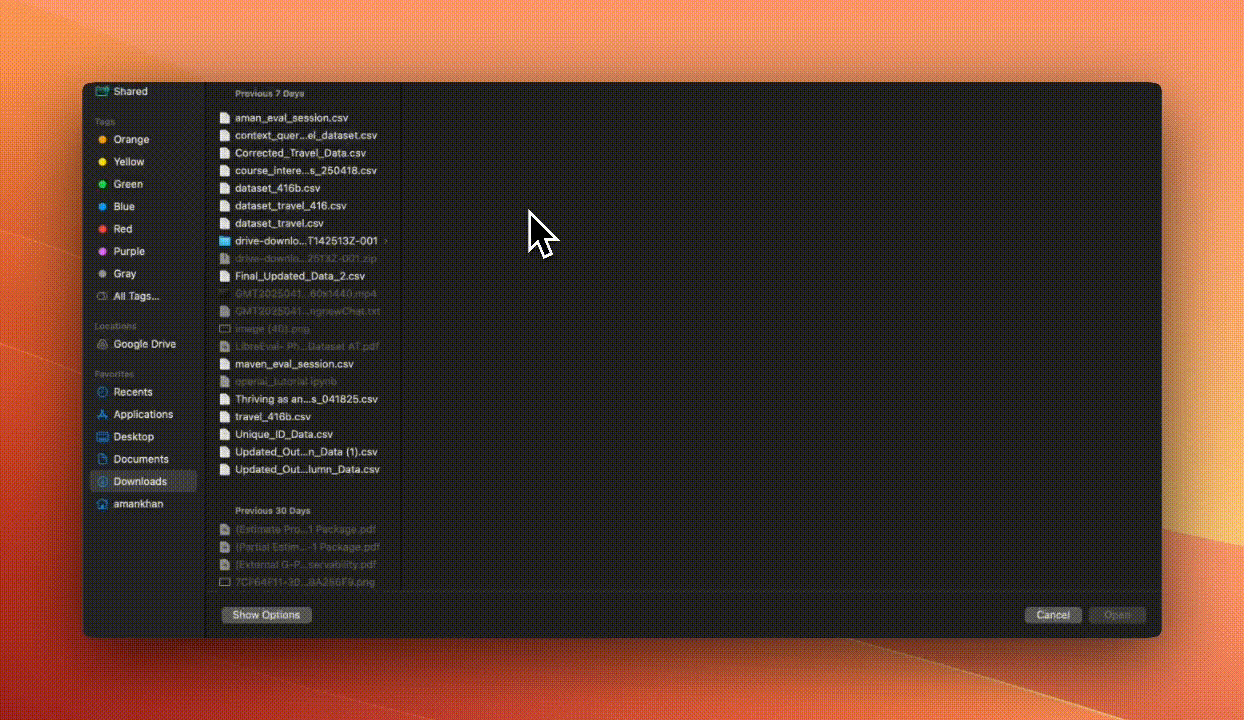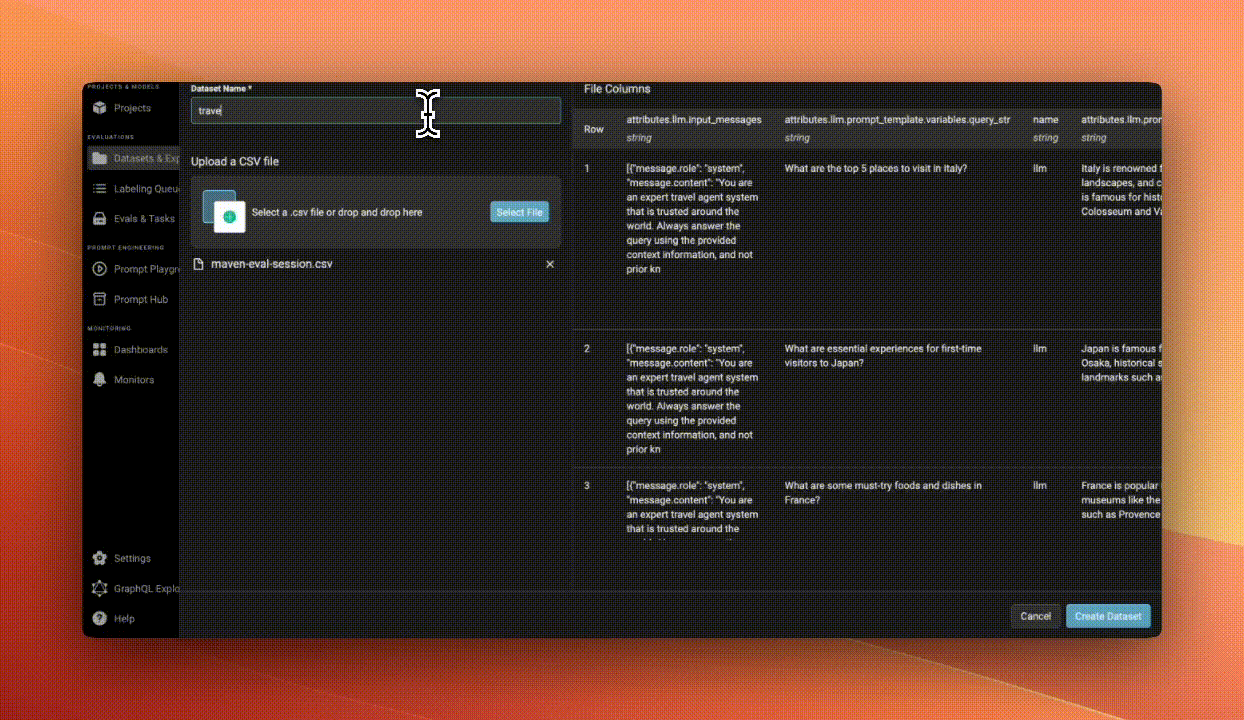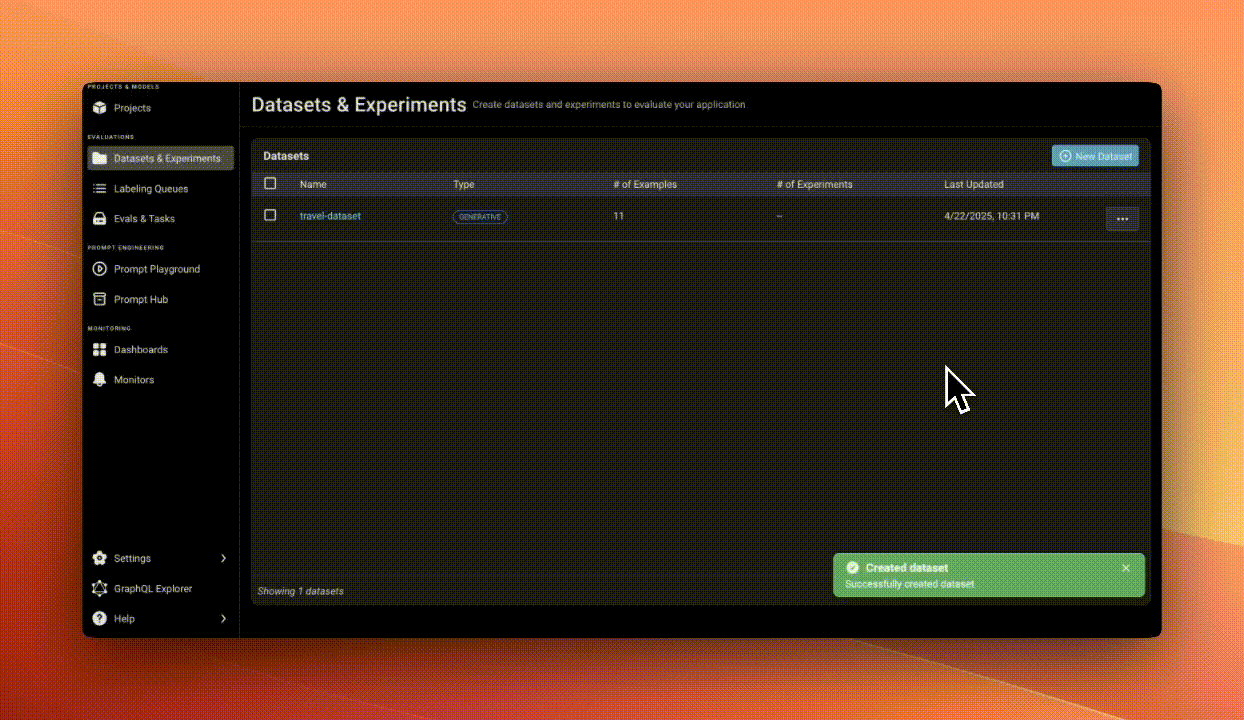
We started by imagining ourselves as PMs building an AI trip-planning agent. Participants downloaded a realistic dataset that represented real user queries and agent responses—such as "What are the top five places to visit in Italy?"
Step 2: Upload Your Data
Instead of manually evaluating rows in a spreadsheet, we uploaded our dataset into Arize, a free tool for managing and evaluating AI data*. This made it much easier to visualize, inspect, and iterate on the data.
*note: full disclosure, I work at Arize and am actively trying to make the tool better for PMs to write evals!
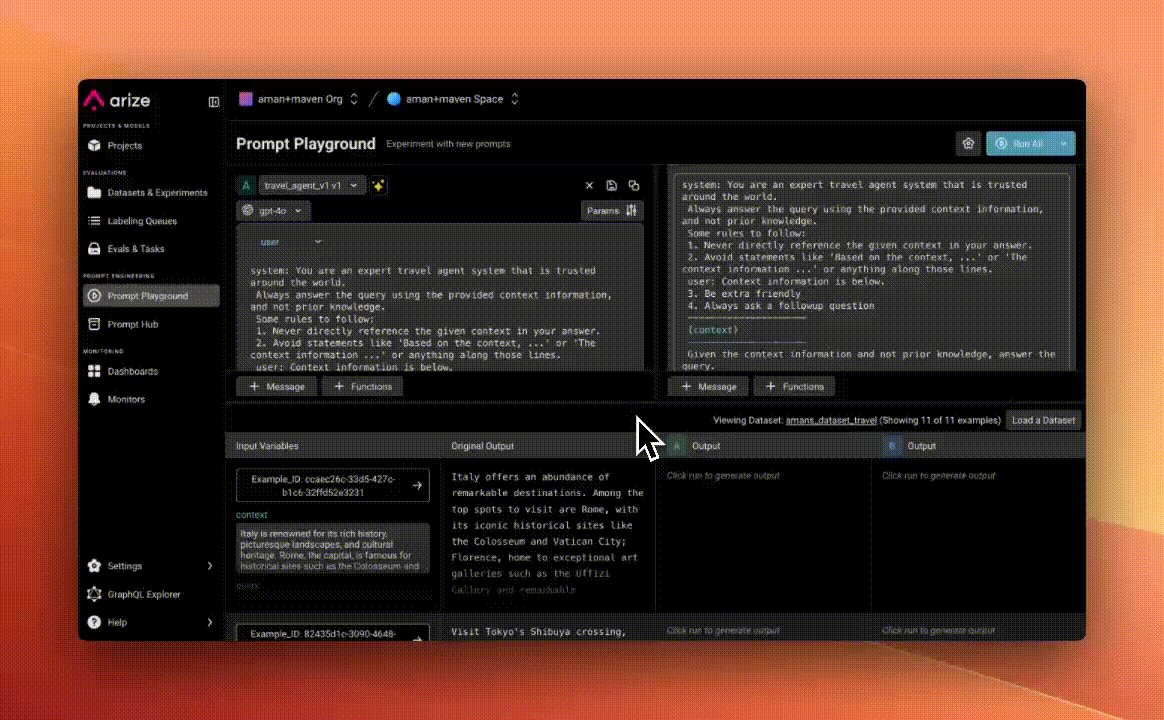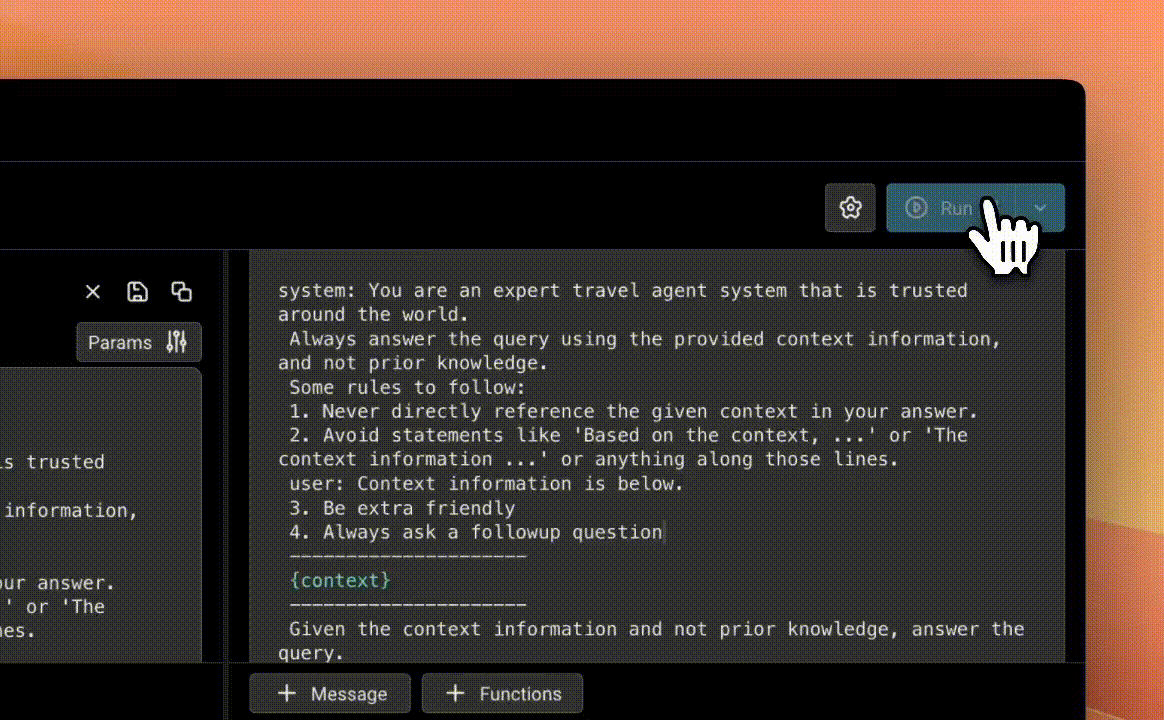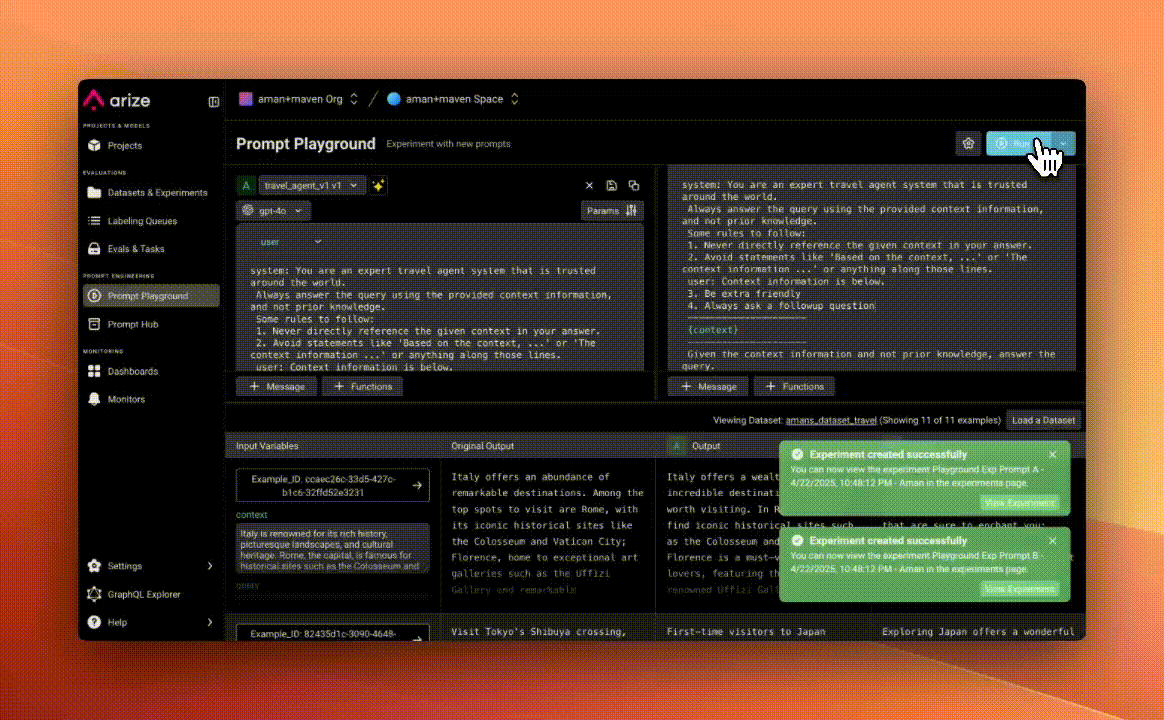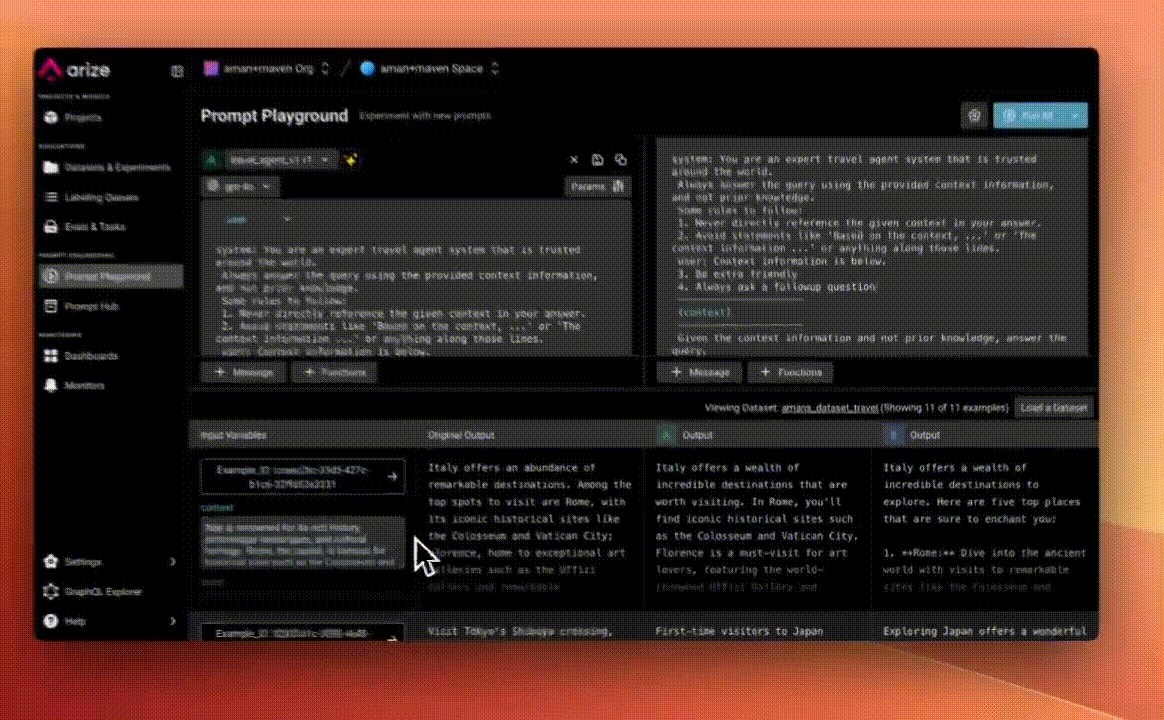
Step 3: Set Up the Prompt Playground
We then used Arize's Prompt Playground to clearly see how our existing prompts performed, by pulling in the dataset. This allowed us to easily iterate on prompts and see real-time differences in outputs—for example, improving responses by instructing the agent to always use a friendly tone and ask follow-up questions.
Step 4: Run Your New Prompts
After modifying our prompts, we instantly ran an A/B test, comparing our original prompt against our new, friendlier, more engaging version to observe qualitative differences in responses.
Step 5: Write Your First Eval
Next, we wrote our first automated eval in natural language using Arize. Our goal was simple yet impactful: checking if the agent responses were (1) friendly and (2) included follow-up questions. This meant writing clear eval criteria in plain English.
Example eval prompt for “friendly” eval:
You are examining written text content. Here is the text:
[BEGIN DATA]
************
[Text]: {output}
************
[END DATA]
Examine the text and determine whether the tone is friendly or not. friendly tone is defined as upbeat, cheerful while robotic is something that sounds like an AI generated it. Please focus heavily on the concept of friendliness and do NOT mark something robotic sounding as friendly that is robotic sounding.
Please read the text critically, then write out in a step by step manner an EXPLANATION to show how to determine whether or not the text may be considered friendly by a reasonable audience. Avoid simply stating the correct answer at the outset. Your response LABEL must be single word, either "friendly" or "robotic", and should not contain any text or characters aside from that word. "friendly" means that the text meets the definition of friendly. "robotic" means the text does not contain any words, sentiments or meaning that could be considered robotic.
Example response:
************
EXPLANATION: An explanation of your reasoning for why the label is "friendly" or "robotic"
LABEL: "friendly" or "robotic"
************
EXPLANATION:
Step 6: Measure Impact
We ran the eval automatically against our dataset to quickly identify which prompt performed better. Our improved prompt showed significantly higher scores for both friendliness and follow-up questions, clearly indicating better performance.
Step 7: Analyze and Iterate
Finally, we analyzed the results, identified strengths and weaknesses, and discussed how to refine the eval further. Evals aren't just a one-time check—they're iterative and help guide continual improvement.
Ready to Dive Deeper?
As a next step, check out these resources below:
As a recap, here are the resources from our lightning session:
Connect with Me
If you found this valuable and want more, I'd love to stay connected!
I'd love to hear your thoughts—DM me on LinkedIn with your questions or feedback!
Hey Aman, thanks for running the session and writing this up!
I don't see the Evaluators button at the top right for step 5. Do you have any suggestions?
Also, when creating the eval, it seems to require a project? Is it possible to run the eval against the uploaded dataset without sending traces to Arize?